Résumé synthétique
PageIndex propose une nouvelle façon d’aborder le RAG pour les documents longs et structurés. Au lieu de se limiter à la similarité entre chunks, l’approche mise davantage sur la structure du document, la navigation raisonnée et la vérifiabilité des réponses.
Au départ, le avait une promesse simple : connecter une IA à des documents pour qu’elle réponde avec des sources, au lieu d’inventer.
Sur le papier, c’est très puissant. En pratique, ça fonctionne bien pour des contenus simples : FAQ, documentation produit, support client, notes internes courtes.
Mais dès qu’on passe à des documents longs et structurés, les limites apparaissent.
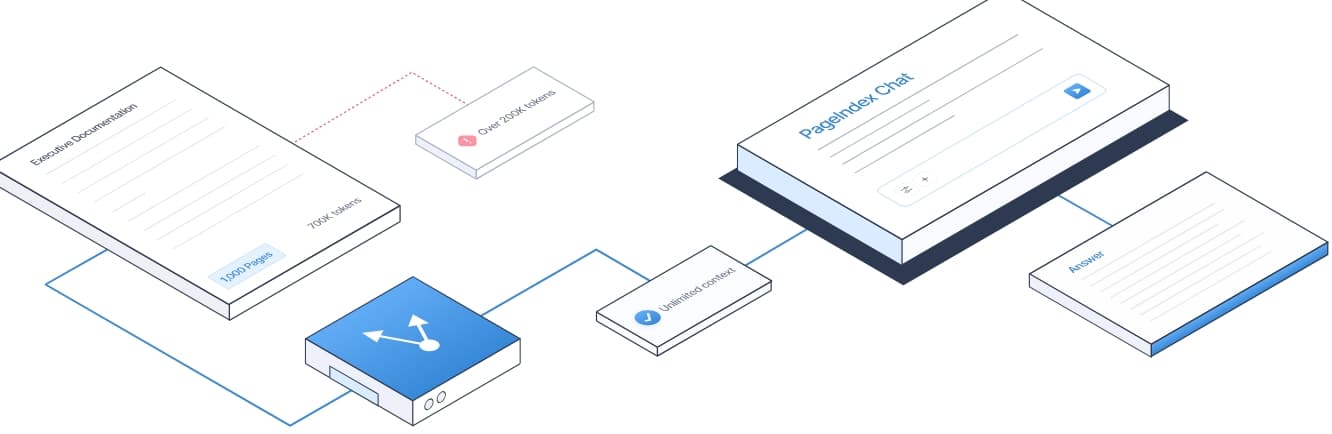
Un rapport annuel, un contrat, une annexe financière ou un document réglementaire ne se lit pas comme une page web classique. Il faut comprendre la structure, suivre des renvois, comparer des tableaux, revenir à une annexe, relier plusieurs sections.
C’est là que PageIndex devient intéressant.
Son idée n’est pas seulement de permettre à l’IA de lire plus de pages. Son vrai apport, c’est d’aider l’IA à savoir où lire, dans quel ordre, et pourquoi.
Pourquoi le RAG classique atteint ses limites
Le classique fonctionne généralement comme ça : on découpe un document en petits morceaux, appelés chunks.
Chaque chunk est ensuite transformé en vecteur, une sorte de représentation mathématique de son sens. Quand l’utilisateur pose une question, le système cherche les chunks les plus proches de cette question.
Cette logique marche bien quand la réponse se trouve dans un passage court et clair.